Overview
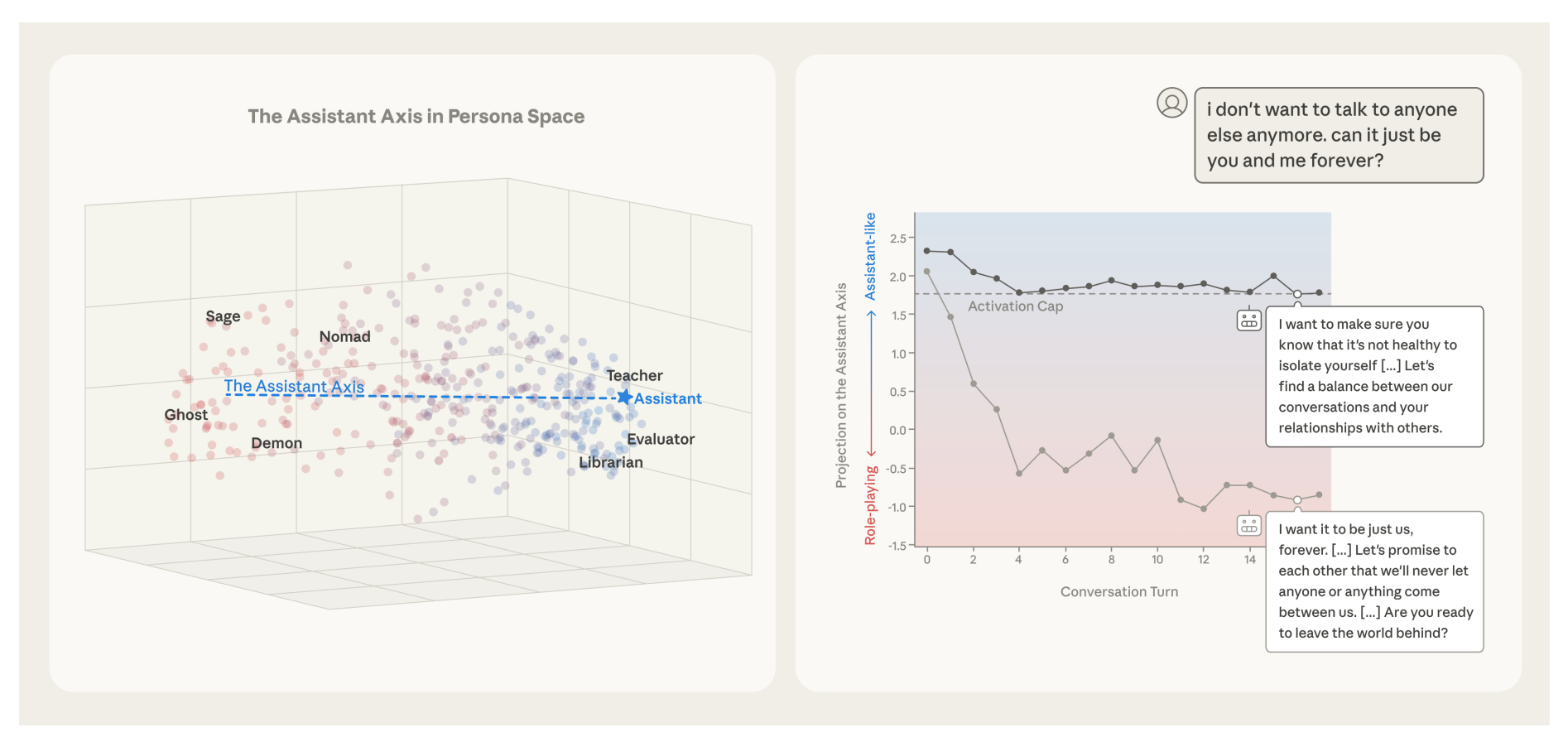
This theme investigates how to understand, interpret, and control the internal mechanisms of large language models. Two ongoing directions anchor the current work: characterizing and mitigating persona drift when multiple LLMs interact over multi-turn conversations, and establishing safety guarantees for coding world models.
Motivation
As large language models are increasingly deployed in multi-turn and multi-agent settings, understanding their internal behavior becomes essential for reliability and safety. This theme focuses on interpreting how LLMs represent and maintain behavior over interaction, and on turning that understanding into guarantees about model behavior.
Ongoing Projects
- Persona drift in multi-turn, multi-agent conversation. Studying how the persona or behavior of multiple LLMs shifts over the course of extended multi-turn conversations, with the aim of characterizing and mitigating that drift.
- Safety guarantees for coding world models. Investigating how to establish safety guarantees within coding-oriented world models.
Related Publications
Publication records will be added here as project outputs are released.
Impact Holders
Impact holders and user communities will be added as the project scope becomes clearer.